

As technology evolves and the world’s population increases, so does the amount of data we generate. As a result, it’s increasingly becoming challenging and time-consuming for businesses to collect, sort, and analyze their data. However, things are getting easier, thanks to the emergence of Machine Learning.
Machine Learning (ML) has been a forefront topic in the business landscape for the last couple of years. According to a recent Deloitte study, over 67% of companies are already using ML in one way or another. Similar research by Statista shows that the global ML market size will record a consistent annual growth rate of 18.73%, reaching an all-time high of $528.10 billion by 2030.
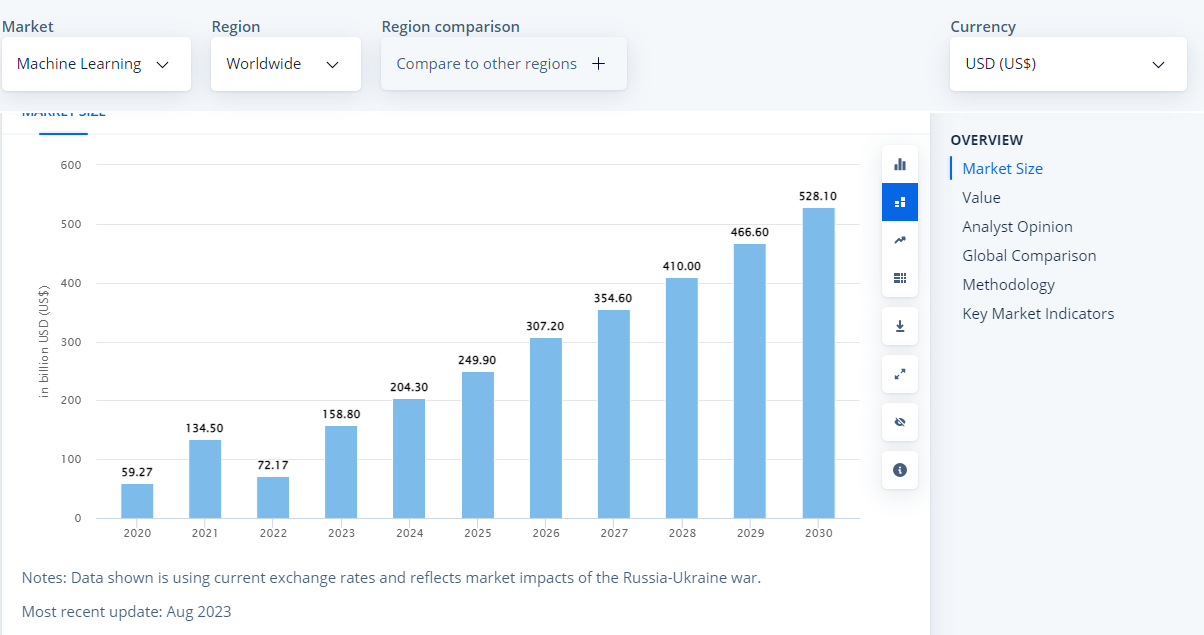
Source: Statista Market Insights
As your go-to LATAM hiring company, we’ve created this guide to give you a current overview of the evolution of machine learning and help you understand what it entails and its potential benefits to your business. The article also discusses why you should seriously consider LATAM for nearshoring ML talent.

Machine Learning Current Landscape and Business Applications
Machine learning (ML) is a branch of computer science that deals with empowering computer systems to learn and improve on their own. In the past, computers could only do what developers and users programmed or commanded them to do. However, thanks to ML, they can now learn from past experiences like humans and improve their accuracy, efficiency, and performance based on previous interactions.
While it’s not mandatory (especially for non-technical staff) to understand the intricacies of ML, its algorithms, feature vectors, models, and so on, learning the basics is instrumental. It can help you understand the interrelationship between this technology and your business processes, identify and avert potential challenges, and, most importantly, understand what to look for when hiring ML engineers.
To get us started, below are a few current applications of machine learning to business processes:
- Image Classification
This is arguably the most common application of ML to business operations. It involves training algorithms to analyze and classify images based on their content. Doing so can help companies minimize errors in operations that involve processing images, such as customer identification.
Source: X (Twitter Screenshot)
A more relatable example is the filtering of nude or offensive images by social platforms like Facebook, Instagram, and Twitter. These platforms don’t have dedicated employees reviewing each post to ensure they’re clean. No. Instead, they’ve trained their systems to flag specific features that characterize offensive images.
- Text Parsing
Text parsing involves training computer programs to decipher and process human-generated texts. It uses natural language processing (NLP). The more you train AI algorithms on the rules of a specific language, the better they become at analyzing its texts to draw insights. This enables computers to interpret large datasets more accurately using less time, eliminating the need for manual labor.
- Recommendation Engines
When your business is young, you might have the advantage of knowing every customer personally — enabling you to make individual communications. However, as your client base grows to hundreds or thousands, not even a dedicated sales team can have the capacity to give each customer personalized attention. And that’s where machine learning comes in.
You can train ML algorithms to process user’s data — such as their purchase histories, abandoned carts, income levels, and demographics — and create models of their potential preferences. These recommendation engines can help businesses improve user experiences and craft targeted campaign content that is more likely to drive conversions.
- Customer Service Through Chatbots
Another common business application of ML is interactive chatbot interfaces. Instead of hiring additional support personnel, organizations can train algorithms to identify and resolve common customer complaints in real time. Doing so saves them resources and ensures they don’t keep clients waiting, reducing the chances of customer churn.
- Predictive Modeling
This application of ML involves mining and analyzing datasets to identify patterns and forecast future outcomes. The predictions can then help executives make better-informed business decisions faster. They can also help identify potential challenges and deploy proactive remedies.
A common practical application of predictive modeling is sales forecasting. By analyzing clients’ purchase histories, businesses can predict their future sales patterns. The inventory department can then use this foresight to make informed restocking decisions, reducing unnecessary overhead costs.
- Fraud Detection
Businesses can also leverage machine learning’s ability to detect patterns and deviations for fraud detection. This application is very common in banking services. They typically deploy ML algorithms in their systems to learn customers’ behaviors, such as their withdrawal frequencies, amounts, and locations. In case of transactions deviating from expected norms, the ML systems can generate potential fraud alerts, enabling banks and their customers to catch scammers.
- Market Research & Customer Segmentation
The adage goes — whatever the market wants, the market wants. Therefore, the onus is on business leaders to identify and deliver what their potential customers desire before the competition.
Machine learning tools can help you gather and analyze customer responses to understand their perceptions of your products and derive insights into their preferences. This enables you to create products and marketing campaigns that target prospects’ specific needs. You can also apply advanced ML techniques like deep learning to identify patterns within subsets of your data, enabling you to segment target audiences based on their unique preferences. The more relevant customers find your offerings, the more likely you’ll pique their interest.
- Customer Churn Modeling
Machine learning can also help businesses identify and avert causes of customer churn. You can train ML models to analyze historical data and evaluate existing customer behavior to spot those who are more likely to leave soon and why they might take their business elsewhere. Next, you can use the generated insight to determine how to keep them longer and extend their client lifetime value (CLTV).
Machine Learning Future Trends
While most of the underlying concepts of ML date back to the 1950s, the technology is gradually advancing in response to emerging challenges and market demands. As we look ahead to the future, the following trends are likely to have significant impacts on ML’s development and adoption:
#1 Explainable AI
While there’s no denying that most ML models have been impressively effective and accurate, we cannot overlook the underlying concern of their transparency. Currently, most ML algorithms rely on “black box” calculations that not even their designers understand. This inability to comprehend how ML systems arrive at their results makes it challenging to identify and avert their potential bias and estimate expected impacts. In response, data scientists and ML engineers have begun championing the adoption of Explainable AI ( XAI) that offers insights into how ML models arrive at specific decisions. This trend will not only increase the general public’s trust in ML but also enhance accountability.
#2 Autonomous Machine Learning
Designing, training, deploying, and managing ML systems requires considerable domain expertise and industry experience. These processes often involve a lot of back and forth that can last forever. It typically takes 6 -8 months to complete a single ML project. However, with the emergence of Autonomous AI (AutoML), these challenges may soon be a thing of the past. AutoML automates routine processes, such as model selection, feature engineering, and hyperparameter tuning. Doing so streamlines ML development, making it easier for even those with limited AI expertise to understand how the technology operates.
#3 Computer Vision
Technically speaking, this is not a new trend. Besides the Large Language Model (LLM), computer vision is one of the ML concepts that has attracted significant business interest for the last couple of decades. According to a recent Insight survey, about 10% of organizations currently use the technology, with 81% analyzing it for future implementation. With the ongoing improvements in object identifiers and image classifiers, we are likely to see a tremendous adoption of computer vision in the near future. Among the areas likely to benefit from this trend include advanced driver assistance, inventory management through AI object identification systems, and facial recognition.
#4 Edge Machine Learning
As more companies adopt the Internet of Things (IoT), it’s increasingly becoming crucial for them to process data at touchpoints in real-time. Besides generating faster insights, edge machine learning can help businesses sort security breaches and latency issues commonly associated with transporting data to distant clouds before feeding it to ML systems. By integrating ML/AI at the data source, businesses are also able to avert connectivity and bandwidth concerns.
#5 Reinforcement Learning
Most ML engineers currently use two primary ML methods: Supervised and Unsupervised learning.
Supervised Machine Learning involves using labeled datasets to train ML algorithms to predict future outcomes and classify data more accurately. Labeled data means that you already have a desired output. A perfect example is the ML program we previously discussed — the programmer trains the ML system to identify different fruits using labeled examples. The model’s role, in this case, is simply to map the input to the output.
Comparatively, Unsupervised Learning trains machines using unlabeled data. Because the data is unparalleled, there’s no fixed output variable. Instead, the model analyzes the data to discover less obvious patterns, features, and insights. For example, imagine an ML program that uses borrowers’ data to determine whether they qualify for loans. The model can learn by analyzing different variables like the borrower’s employment status, income level, financial commitments, and loan repayment histories to mark them as high-risk or low-risk customers. Based on this insight, you can decide whether to lend them or not.
While the two methods have dominated the ML scene for a long time, a new kid on the block, reinforcement learning, is tremendously gaining traction. This type of ML uses an agent (algorithm) that learns through the rewards it receives from interacting with its environment. Using the bank loan example above, let’s say a reinforced learning algorithm marks a borrower as low-risk. If they pay their loans on time, the agent gets a positive reward, prompting it to make similar decisions in the future. Comparatively, if the borrower defaults, the algorithm gets a negative reward, prompting it to change or improve its decision-making process. The trial-and-error approach makes Reinforcement Learning more responsive than the other two methods.
Do You Need a LATAM Engineer?
Machine learning is a vast and sophisticated concept. We’ve barely covered the basics. Therefore, unless you’re an expert in this field, you’ll definitely need the help of a seasoned ML engineer. Even if you’re a trained ML specialist, implementing this technology can consume your valuable time and take your focus off other valuable tasks. So, you might still need a dedicated engineer.
ML engineers typically perform the following tasks:
- Evaluating your business needs and operations to determine how ML can help improve them
- Researching and applying data analytics
- Creating and deploying new ML models
- Assessing existing ML frameworks and libraries to identify improvement opportunities
- Training ML systems and evaluating their application cases and problem-solving potentials
- Developing ML apps based on client specifications
Do these professionals replace your existing tech teams? The simple answer is — No. In most cases, organizations hire them on a need-basis to work on specific projects alongside in-house IT departments. They can train the internal team on updating and maintaining the ML system after their departure.
LATAM as a Bustling Hub of ML Engineers
Once known as the land of untapped opportunities, LATAM is gradually morphing into the “The Next Silicon Valley.” If you’re planning to establish a remote ML engineering team, you should seriously consider leveraging this region’s potential. Here’s why:
LATAM has a vast pool of competent ML engineers
Latin America is home to over 1.4 million software developers. So, if there’s a place where you’re likely to find a competent ML engineer conveniently, it’s this region. Most of these engineers have an in-depth understanding of software development and ML best practices, thanks to LATAM’s continuous investment in tech-related educational programs. For example, Mexico alone churns over 605,000 software engineering graduates annually.
Cost-saving opportunity
Of course, one of the concerns when hiring ML engineers is the cost factor. ML specialists in Canada and the US earn an average base salary of $106,655 and $160,837 annually, respectively. By any standard, this can be a significant dent in your finances. Fortunately, Latin America offers access to the same quality of ML talent for way less. For example, in Argentina, ML engineers earn an average of $46,923 annually. That’s over half the regular US and Canada fee!
The presence of successful unicorns and tech giants
LATAM has several tech hubs that host myriads of successful unicorns and global tech giants. For example, IBM and Microsoft already have R&D offices in Mexico, Argentina, and Costa Rica. Besides validating the region’s potential, the presence of these established tech firms offers opportunities for LATAM’s tech talent to hone their skills and stay at par with global standards.
Good English skills
Besides software development expertise, ML engineers also require a firm grasp of English to enable them to explain their projects to other non-technical staff. Fortunately, unlike other popular offshoring destinations, most people in Latin America speak English as their first or second language. Also, most universities in the region use English as the learning language. Because of this, you’re less likely to encounter communication issues with LATAM ML engineers.
Timezone and cultural alignment
Despite being down south, LATAM has a very slight time difference with most regions in North America. This timezone alignment makes it easy for business owners to collaborate in real-time with remote teams from this region. Additionally, the region’s workforce enjoys cultural similarities with the rest of the US, so you won’t have to labor explaining your work ethic and values.
Enjoy Flexibility When You Hire LATAM ML Engineers Via DevEngine
While LATAM boasts a vast pool of qualified ML engineers, it requires special skills to find one befitting your unique business needs. Let DevEngine help you get the best talent from this region for your ML projects. We have several protocols to ensure our partners get high-quality, pre-vetted experts with proven track records.
We focus on a few clients at a time
DevEngine prioritizes quality over quantity. To ensure all our clients get personalized attention and care, we only partner with a few at a time. Doing so enables us to dedicate all our energy and resources to the limited client base.
Multilayered screening
While most of our ML engineers are from our proprietary referral system, we still vet each of them thoroughly to ensure they’re qualified and job-ready. The multilayered screening process involves paid pre-vetting, after which we pair successful candidates with our senior engineers for a 360-degree assessment of their ML expertise, industry experience, and cultural fit.
Customized hiring and onboarding
Based on our experience over the years, we understand that every industry and business has unique tech needs that require personalized solutions. That’s why, before we begin the hiring process, we analyze clients’ businesses to identify their operation models, workplace cultures, pain points, and business needs. This approach gives us a holistic understanding of our customers, enabling us to deliver personalized hires.
Transparent pricing
When working with us, you don’t have to worry about hidden costs or hiked service bills. We proactively prevent this through our upfront pricing model. Before listing our services, we’ll discuss the charges and sign a transparent contract. Also, we have flexible payment options for customers who want to pay in installments.
Are you ready to take advantage of Latin America’s deep bench of ML engineers? DevEngine is here to help. We’ve been helping organizations like yours find competent LATAM ML engineers (and other tech talent) since 2019.
Contact us today for a streamlined hiring process.
